Asynchrony (CUDA C++)
问题背景 - CUDA编程往异步化发展要解决什么问题
根因:GPU Memory Wall
- The Memory Wall: Past, Present, and Future of DRAM
- Scaling the Memory Wall: The Rise and Roadmap of HBM
要想发挥GPU/NPU的GEMM算力,核心在于把内存带宽打满,同时要充分发挥cuda core/tensor core的性能。如果tensor core需要计算需要占用per-thread的线程(比如寄存器)的话,一方面影响cuda core的性能(寄存器不够用),一方面影响tensor core性能(寄存器数量限制硬件MMA的大小,同时不利于计算/拷贝的遮掩,因为一般这需要N倍的寄存器空间)。寄存器过多进一步导致无法launch足够的warp来掩盖memory latency,会让性能进一步下降。
因此总体的Tensor Core架构演进在于将cuda core和tensor core的硬件资源结构,从而充分发挥各自的性能(比如,tensor core做MM,cuda core做epilogue操作)。
- Hopper:通过TMA将数据拷贝和寄存器解耦;WGMMA的异步化,提升cuda core/tensor core的利用率
- Blackwell: 通过Tensor Memory将MMA指令与寄存器解耦,从而使tensor core的数据通路不再依赖寄存器
洞察:Nvidia为了布局异步编程能力,将异步编程中和CPU兼容的部分贡献到C++标准(包括C++20 barrier, latch等,以及重磅的C++26 std::execution等);其他只和GPU相关的部分放在CUDA C++中(libcu++库)。
前置知识:C++异步屏障std::barrier
经典屏障比如pthread barrier,OpenMP barrier,CUDA __syncthreads()既是arrive也是wait
std::barrier是一种可以被重复使用的同步原语。它用于让多个线程等待,直到所有线程(arrival count)都到达屏障点,然后一起继续执行。一旦所有线程都到达了屏障,它们便可以同时继续运行,并且该屏障可以被重复用于下一次同步。C++20 std::barrier实现了arrive和wait的分离。下面是一个简单的示例:
auto t = barrier.arrive(); // I’m done producing
// While others are still working...
do_next_independent_work(); // <---- overlap work
barrier.wait(t); // wait only when needed
Nvidia GPU上实现了C++20 std::barrier (std::barrier大多数作者来自Nvidia),用来辅助异步拷贝场景下的同步操作。
适用场景
-
同步迭代算法:在许多迭代算法中(尤其是在并行计算中),所有线程必须完成当前迭代后,才能开始下一次迭代。可以使用屏障(barrier)来确保所有线程在每次迭代结束时进行同步。例如:
std::barrier iter_barrier(num_threads); void parallel_algorithm(int thread_id) { for (int i = 0; i < max_iterations; ++i) { // 执行本次迭代的一些并行计算 iter_barrier.arrive_and_wait(); // 在此处等待,直到所有线程都完成本次迭代 } } - 周期性同步:在一种模拟场景中,多个实体(由不同线程管理)需要定期同步它们的状态。屏障(barrier)可以确保所有实体在固定的时间间隔点上进行同步。
- 初始化并行流水线:在数据处理中,如果存在由多个阶段组成的流水线,且每个阶段由一个独立的线程处理,可以使用屏障(barrier)来确保所有流水线阶段都已正确设置并准备就绪,然后再开始传输数据。(warp specialization, producer / consumer)
Memory Fence Functions
| API | equivalent to | Description |
|---|---|---|
void __threadfence_block(); |
cuda::atomic_thread_fence(cuda::memory_order_seq_cst, cuda::thread_scope_block) | |
void __threadfence(); |
cuda::atomic_thread_fence(cuda::memory_order_seq_cst, cuda::thread_scope_device) | |
void __threadfence_system(); |
cuda::atomic_thread_fence(cuda::memory_order_seq_cst, cuda::thread_scope_system) |
Synchronization Functions
| API | Description |
|---|---|
void __syncthreads(); |
|
int __syncthreads_count(int predicate); |
|
int __syncthreads_and(int predicate); |
|
int __syncthreads_or(int predicate); |
|
void __syncwarp(unsigned mask=0xffffffff); |
Distributed Shared Memory (since Hopper)
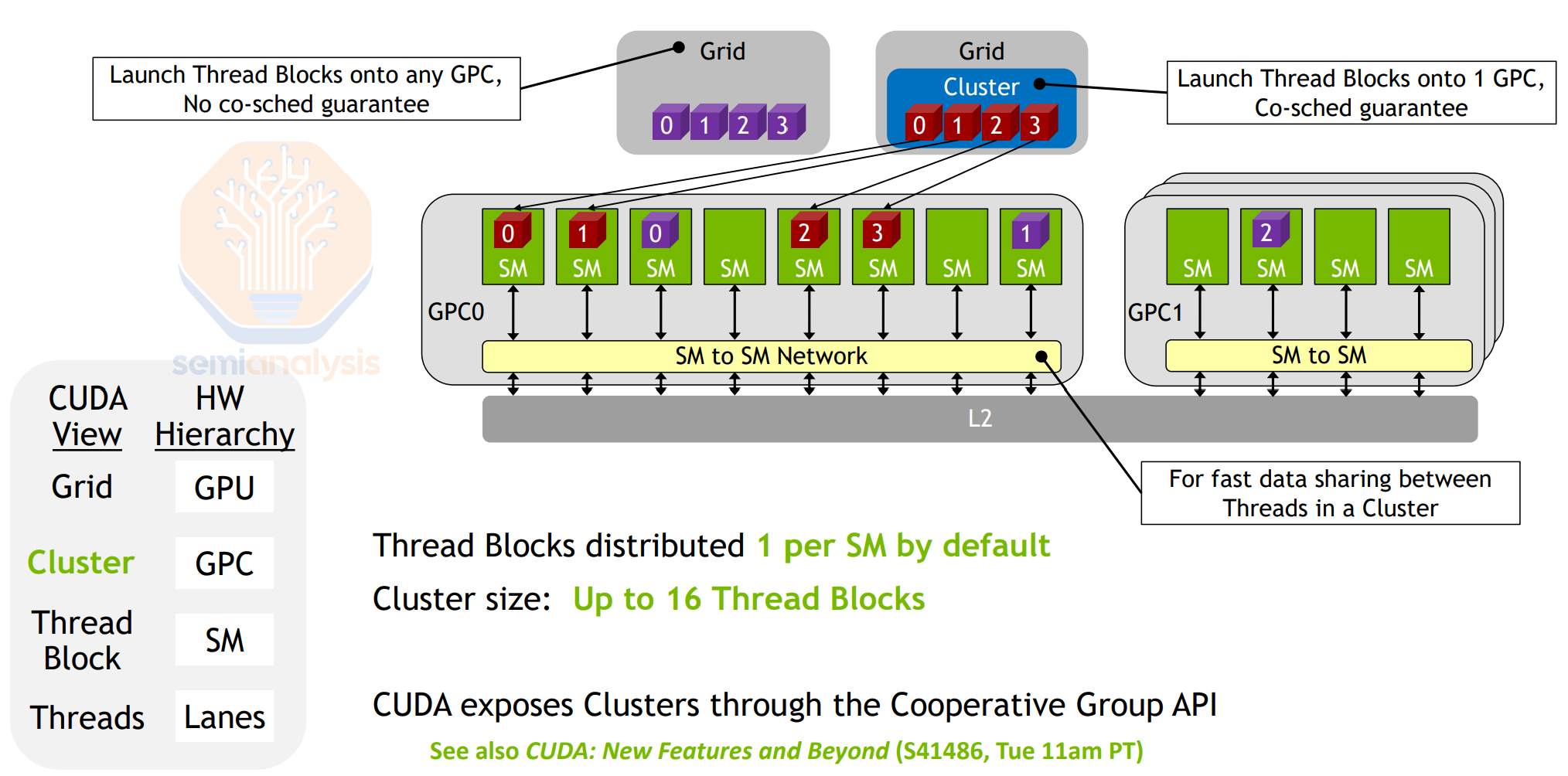
static unsigned int query_shared_rank(const void *addr): Obtain the block rank to which a shared memory address belongs
static T* map_shared_rank(T *addr, int rank): Obtain the address of a shared memory variable of another block in the cluster
#include <cooperative_groups.h>
__cluster_dims__(2)
__global__ void kernel() {
__shared__ int x;
x = 1;
namespace cg = cooperative_groups;
cg::cluster_group cluster = cg::this_cluster();
cluster.sync();
// Get address of remote shared memory value:
unsigned int other_block_rank = cluster.block_rank() ^ 1;
int * remote_x = cluster.map_shared_rank(&bar, other_block_rank);
// Write to remote value:
*remote_x = 2;
}
CUDA异步屏障cuda::barrier
cuda::barrier = std::barrier + transaction count
除了到达计数(arrival count)之外,cuda::barrier<thread_scope_block> 对象还支持一个事务计数(tx-count),用于跟踪异步内存操作的完成情况。该 tx-count 记录尚未完成的异步内存操作的数量(单位通常为字节)。相比std::barrier,cuda::barrier新增以下方法:
| Method | Description |
|---|---|
| cuda::barrier::init | Initialize a cuda::barrier. |
| cuda::device::barrier_native_handle | Get the native handle to a cuda::barrier. |
| cuda::device::barrier_arrive_tx | Arrive on a cuda::barrier<cuda::thread_scope_block> with transaction count update. |
| cuda::device::barrier_expect_tx | Update transaction count of cuda::barrier<cuda::thread_scope_block>. |
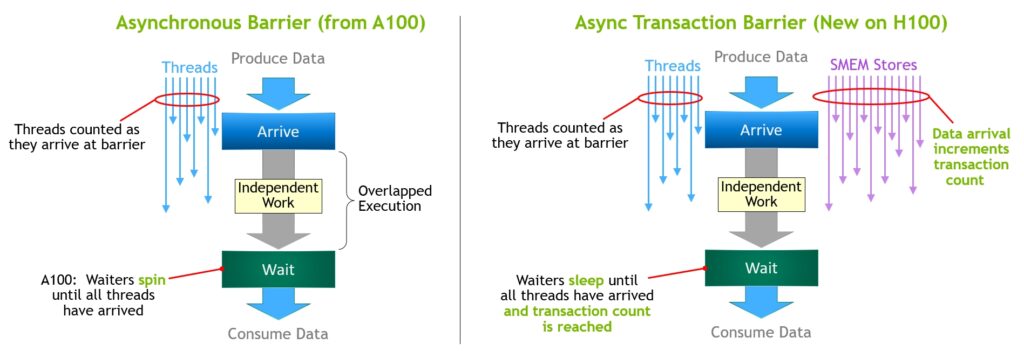
在加入barrier支持之前,CUDA有以下手段进行同步:
- thread block - level synchronization (e.g.,
__syncthreads()); - warp-level synchronization (e.g.,
__syncwarp()); and - thread-level fence operations.
这里有两个有关系但是不同的逻辑概念:
-
屏障(barrier)是指线程之间的关系
“我是线程A,我需要等线程B,C,D完成后再继续执行”
-
内存屏障(memory barrier, memory fence)是用来实现内存可见性规则
“Everyone who can see my writes must see them before X.”
C++20 std::barrier只是同步机制,不是内存屏障;cuda::barrier既是同步机制,也是内存屏障;__syncthreads()既是同步机制,也是内存屏障
简单同步,不用std::barrier
-
用
__syncthreads()或者 Cooperative Groups sync - 既线程间同步,也是memory fence(
atomic_thread_fence(memory_order_seq_cst, thread_scope_block)) -
一个例子:
#include <cooperative_groups.h> __global__ void simple_sync(int iteration_count) { auto block = cooperative_groups::this_thread_block(); for (int i = 0; i < iteration_count; ++i) { /* code before arrive */ block.sync(); /* wait for all threads to arrive here */ /* code after wait */ } }
cuda::barrier完整示例
arrive and then wait模式包含五个阶段:
arrive前的代码:执行将在wait之后被读取的内存更新操作。- 到达点(arrive point):包含一个隐式的内存屏障(即等效于
atomic_thread_fence(memory_order_seq_cst, thread_scope_block))。arrive与wait之间的代码:在调用arrive之后、wait之前执行的代码。- 等待点(wait point):线程在此处阻塞,直到所有参与线程都已到达屏障。
wait之后的代码:在此阶段,线程能够看到其他线程在各自arrive之前所执行的内存更新。
一个例子:
#include <cuda/barrier>
#include <cooperative_groups.h>
__device__ void compute(float* data, int curr_iteration);
__global__ void split_arrive_wait(int iteration_count, float *data) {
using barrier = cuda::barrier<cuda::thread_scope_block>;
__shared__ barrier bar;
auto block = cooperative_groups::this_thread_block();
if (block.thread_rank() == 0) {
init(&bar, block.size()); // Initialize the barrier with expected arrival count
}
block.sync();
for (int curr_iter = 0; curr_iter < iteration_count; ++curr_iter) {
/* code before arrive */
barrier::arrival_token token = bar.arrive(); /* this thread arrives. Arrival does not block a thread */
compute(data, curr_iter);
bar.wait(std::move(token)); /* wait for all threads participating in the barrier to complete bar.arrive()*/
/* code after wait */
}
}
cuda::barrier初始化
#include <cuda/barrier>
#include <cooperative_groups.h>
__global__ void init_barrier() {
__shared__ cuda::barrier<cuda::thread_scope_block> bar;
auto block = cooperative_groups::this_thread_block();
if (block.thread_rank() == 0) {
init(&bar, block.size()); // Single thread initializes the total expected arrival count.
}
block.sync();
}
cuda::barrier生命周期
cuda::barrier可以被复用,一次完整的使用称为phase,每个phase有这几个步骤:
- Arrival
- Countdown
- Completion
- and Reset
线程块Spatial Partitioning (also known as Warp Specialization)
用来实现producer/consumer模式。一个warp的所有线程或者是producer,或者是consumer,不能同时是producer和consumer。
#include <cuda/barrier>
#include <cooperative_groups.h>
using barrier = cuda::barrier<cuda::thread_scope_block>;
__device__ void producer(barrier ready[], barrier filled[], float* buffer, float* in, int N, int buffer_len)
{
for (int i = 0; i < (N/buffer_len); ++i) {
ready[i%2].arrive_and_wait(); /* wait for buffer_(i%2) to be ready to be filled */
/* produce, i.e., fill in, buffer_(i%2) */
barrier::arrival_token token = filled[i%2].arrive(); /* buffer_(i%2) is filled */
}
}
__device__ void consumer(barrier ready[], barrier filled[], float* buffer, float* out, int N, int buffer_len)
{
barrier::arrival_token token1 = ready[0].arrive(); /* buffer_0 is ready for initial fill */
barrier::arrival_token token2 = ready[1].arrive(); /* buffer_1 is ready for initial fill */
for (int i = 0; i < (N/buffer_len); ++i) {
filled[i%2].arrive_and_wait(); /* wait for buffer_(i%2) to be filled */
/* consume buffer_(i%2) */
barrier::arrival_token token = ready[i%2].arrive(); /* buffer_(i%2) is ready to be re-filled */
}
}
//N is the total number of float elements in arrays in and out
__global__ void producer_consumer_pattern(int N, int buffer_len, float* in, float* out) {
// Shared memory buffer declared below is of size 2 * buffer_len
// so that we can alternatively work between two buffers.
// buffer_0 = buffer and buffer_1 = buffer + buffer_len
__shared__ extern float buffer[];
// bar[0] and bar[1] track if buffers buffer_0 and buffer_1 are ready to be filled,
// while bar[2] and bar[3] track if buffers buffer_0 and buffer_1 are filled-in respectively
__shared__ barrier bar[4];
auto block = cooperative_groups::this_thread_block();
if (block.thread_rank() < 4)
init(bar + block.thread_rank(), block.size());
block.sync();
if (block.thread_rank() < warpSize)
producer(bar, bar+2, buffer, in, N, buffer_len);
else
consumer(bar, bar+2, buffer, out, N, buffer_len);
}
异步数据拷贝(Asynchronous Data Copies)
memcpy_async API
| API | 同步原语 |
|---|---|
cuda::memcpy_async |
cuda::barrier/ cuda::pipeline |
cooperative_groups::memcpy_async |
cooperative_groups::wait |
Copy and Compute Pattern - Staging Data Through Shared Memory
CUDA应用典型场景copy and compute :
- 从GMEM拷贝数据到SMEM
- 在SMEM的数据上做计算
- (可选)把数据从SMEM拷贝回GMEM
有以下几种典型同步或者异步的方式实现copy and compute
同步拷贝,不用memcpy_async
需要经过RMEM
#include <cooperative_groups.h>
__device__ void compute(int* global_out, int const* shared_in);
__global__ void without_memcpy_async(int* global_out, int const* global_in, size_t size, size_t batch_sz) {
auto grid = cooperative_groups::this_grid();
auto block = cooperative_groups::this_thread_block();
assert(size == batch_sz * grid.size()); // Exposition: input size fits batch_sz * grid_size
extern __shared__ int shared[]; // block.size() * sizeof(int) bytes
size_t local_idx = block.thread_rank();
for (size_t batch = 0; batch < batch_sz; ++batch) {
// Compute the index of the current batch for this block in global memory:
size_t block_batch_idx = block.group_index().x * block.size() + grid.size() * batch;
size_t global_idx = block_batch_idx + threadIdx.x;
shared[local_idx] = global_in[global_idx];
block.sync(); // Wait for all copies to complete
compute(global_out + block_batch_idx, shared); // Compute and write result to global memory
block.sync(); // Wait for compute using shared memory to finish
}
}
用cooperative_groups::memcpy_async异步拷贝,用cooperative_groups::wait同步
异步拷贝,不经过RMEM,底层调用cp.async
#include <cooperative_groups.h>
#include <cooperative_groups/memcpy_async.h>
__device__ void compute(int* global_out, int const* shared_in);
__global__ void with_memcpy_async(int* global_out, int const* global_in, size_t size, size_t batch_sz) {
auto grid = cooperative_groups::this_grid();
auto block = cooperative_groups::this_thread_block();
assert(size == batch_sz * grid.size()); // Exposition: input size fits batch_sz * grid_size
extern __shared__ int shared[]; // block.size() * sizeof(int) bytes
for (size_t batch = 0; batch < batch_sz; ++batch) {
size_t block_batch_idx = block.group_index().x * block.size() + grid.size() * batch;
// Whole thread-group cooperatively copies whole batch to shared memory:
cooperative_groups::memcpy_async(block, shared, global_in + block_batch_idx, sizeof(int) * block.size());
cooperative_groups::wait(block); // Joins all threads, waits for all copies to complete
compute(global_out + block_batch_idx, shared);
block.sync();
}
}}
用cuda::memcpy_async异步拷贝,用cuda::barrier同步
#include <cooperative_groups.h>
#include <cuda/barrier>
__device__ void compute(int* global_out, int const* shared_in);
__global__ void with_barrier(int* global_out, int const* global_in, size_t size, size_t batch_sz) {
auto grid = cooperative_groups::this_grid();
auto block = cooperative_groups::this_thread_block();
assert(size == batch_sz * grid.size()); // Assume input size fits batch_sz * grid_size
extern __shared__ int shared[]; // block.size() * sizeof(int) bytes
// Create a synchronization object (C++20 barrier)
__shared__ cuda::barrier<cuda::thread_scope::thread_scope_block> barrier;
if (block.thread_rank() == 0) {
init(&barrier, block.size()); // Friend function initializes barrier
}
block.sync();
for (size_t batch = 0; batch < batch_sz; ++batch) {
size_t block_batch_idx = block.group_index().x * block.size() + grid.size() * batch;
cuda::memcpy_async(block, shared, global_in + block_batch_idx, sizeof(int) * block.size(), barrier);
barrier.arrive_and_wait(); // Waits for all copies to complete
compute(global_out + block_batch_idx, shared);
block.sync();
}
}
cuda::pipeline
cuda::pipeline的完整API在libcu++。A pipeline object is a double-ended N stage queue with a head and a tail, and is used to process work in a first-in first-out (FIFO) order. The class template cuda::pipeline provides a coordination mechanism which can sequence asynchronous operations, such as cuda::memcpy_async, into stages.
A thread interacts with a pipeline stage using the following pattern:
- Acquire the pipeline stage.
- Commit some operations to the stage.
- Wait for the previously committed operations to complete.
- Release the pipeline stage.
For cuda::thread_scope s other than cuda::thread_scope_thread, a cuda::pipeline_shared_state is required to coordinate the participating threads.
Pipelines can be either unified or partitioned. In a unified pipeline, all the participating threads are both producers and consumers. In a partitioned pipeline, each participating thread is either a producer or a consumer.
cuda::pipeline_role:在partitioned producer/consumer pipeline中,标记一个线程是producer还是consumer。
cuda::pipeline_shared_state:协调参与 cuda::pipeline 的线程的状态
Single-Stage Asynchronous Data Copies using cuda::pipeline
with_single_stage: 此示例所有线程既是producer也是consumer(也称为unified pipeline)。线程会立即等待数据传输到共享内存完成。这样避免了将数据从全局内存直接传入寄存器,但并未通过与计算重叠来隐藏 memcpy_async 操作的延迟。
#include <cooperative_groups/memcpy_async.h>
#include <cuda/pipeline>
__device__ void compute(int* global_out, int const* shared_in);
__global__ void with_single_stage(int* global_out, int const* global_in, size_t size, size_t batch_sz) {
auto grid = cooperative_groups::this_grid();
auto block = cooperative_groups::this_thread_block();
assert(size == batch_sz * grid.size()); // Assume input size fits batch_sz * grid_size
constexpr size_t stages_count = 1; // Pipeline with one stage
// One batch must fit in shared memory:
extern __shared__ int shared[]; // block.size() * sizeof(int) bytes
// Allocate shared storage for a single stage cuda::pipeline:
__shared__ cuda::pipeline_shared_state<
cuda::thread_scope::thread_scope_block,
stages_count
> shared_state;
auto pipeline = cuda::make_pipeline(block, &shared_state);
// Each thread processes `batch_sz` elements.
// Compute offset of the batch `batch` of this thread block in global memory:
auto block_batch = [&](size_t batch) -> int {
return block.group_index().x * block.size() + grid.size() * batch;
};
for (size_t batch = 0; batch < batch_sz; ++batch) {
size_t global_idx = block_batch(batch);
// Collectively acquire the pipeline head stage from all producer threads:
pipeline.producer_acquire();
// Submit async copies to the pipeline's head stage to be
// computed in the next loop iteration
cuda::memcpy_async(block, shared, global_in + global_idx, sizeof(int) * block.size(), pipeline);
// Collectively commit (advance) the pipeline's head stage
pipeline.producer_commit();
// Collectively wait for the operations committed to the
// previous `compute` stage to complete:
pipeline.consumer_wait();
// Computation overlapped with the memcpy_async of the "copy" stage:
compute(global_out + global_idx, shared);
// Collectively release the stage resources
pipeline.consumer_release();
}
}
Multi-Stage Asynchronous Data Copies using cuda::pipeline
with-staging: 此示例所有线程既是producer也是consumer(也称为unified pipeline)。以下示例实现了一个两阶段流水线,将数据传输与计算重叠执行。
#include <cooperative_groups/memcpy_async.h>
#include <cuda/pipeline>
__device__ void compute(int* global_out, int const* shared_in);
__global__ void with_staging(int* global_out, int const* global_in, size_t size, size_t batch_sz) {
auto grid = cooperative_groups::this_grid();
auto block = cooperative_groups::this_thread_block();
assert(size == batch_sz * grid.size()); // Assume input size fits batch_sz * grid_size
constexpr size_t stages_count = 2; // Pipeline with two stages
// Two batches must fit in shared memory:
extern __shared__ int shared[]; // stages_count * block.size() * sizeof(int) bytes
size_t shared_offset[stages_count] = { 0, block.size() }; // Offsets to each batch
// Allocate shared storage for a two-stage cuda::pipeline:
__shared__ cuda::pipeline_shared_state<
cuda::thread_scope::thread_scope_block,
stages_count
> shared_state;
auto pipeline = cuda::make_pipeline(block, &shared_state);
// Each thread processes `batch_sz` elements.
// Compute offset of the batch `batch` of this thread block in global memory:
auto block_batch = [&](size_t batch) -> int {
return block.group_index().x * block.size() + grid.size() * batch;
};
// Initialize first pipeline stage by submitting a `memcpy_async` to fetch a whole batch for the block:
if (batch_sz == 0) return;
pipeline.producer_acquire();
cuda::memcpy_async(block, shared + shared_offset[0], global_in + block_batch(0), sizeof(int) * block.size(), pipeline);
pipeline.producer_commit();
// Pipelined copy/compute:
for (size_t batch = 1; batch < batch_sz; ++batch) {
// Stage indices for the compute and copy stages:
size_t compute_stage_idx = (batch - 1) % 2;
size_t copy_stage_idx = batch % 2;
size_t global_idx = block_batch(batch);
// Collectively acquire the pipeline head stage from all producer threads:
pipeline.producer_acquire();
// Submit async copies to the pipeline's head stage to be
// computed in the next loop iteration
cuda::memcpy_async(block, shared + shared_offset[copy_stage_idx], global_in + global_idx, sizeof(int) * block.size(), pipeline);
// Collectively commit (advance) the pipeline's head stage
pipeline.producer_commit();
// Collectively wait for the operations committed to the
// previous `compute` stage to complete:
pipeline.consumer_wait();
// Computation overlapped with the memcpy_async of the "copy" stage:
compute(global_out + global_idx, shared + shared_offset[compute_stage_idx]);
// Collectively release the stage resources
pipeline.consumer_release();
}
// Compute the data fetch by the last iteration
pipeline.consumer_wait();
compute(global_out + block_batch(batch_sz-1), shared + shared_offset[(batch_sz - 1) % 2]);
pipeline.consumer_release();
}
with_specialized_staging_unified: 此示例rank为偶数的线程是producer;rank为奇数的线程是consumer(也称为partitioned pipeline)。注意:这个例子没有使用warp specialization,因为一个warp里的thread,有的是producer,有的是consumer;而warp specialization要求warp里的所有thread做同样的操作。
__device__ void compute(int* global_out, int shared_in);
// "specialized" in the API means this uses partitioned pipeline;
// "unified" means the prologue and epilogue are folded into the loop
template <size_t stages_count = 2>
__global__ void with_specialized_staging_unified(int* global_out, int const* global_in, size_t size, size_t batch_sz) {
auto grid = cooperative_groups::this_grid();
auto block = cooperative_groups::this_thread_block();
// In this example, threads with "even" thread rank are producers, while threads with "odd" thread rank are consumers:
const cuda::pipeline_role thread_role
= block.thread_rank() % 2 == 0? cuda::pipeline_role::producer : cuda::pipeline_role::consumer;
// Each thread block only has half of its threads as producers:
auto producer_threads = block.size() / 2;
// Map adjacent even and odd threads to the same id:
const int thread_idx = block.thread_rank() / 2;
auto elements_per_batch = size / batch_sz;
auto elements_per_batch_per_block = elements_per_batch / grid.group_dim().x;
extern __shared__ int shared[]; // stages_count * elements_per_batch_per_block * sizeof(int) bytes
size_t shared_offset[stages_count];
for (int s = 0; s < stages_count; ++s) shared_offset[s] = s * elements_per_batch_per_block;
__shared__ cuda::pipeline_shared_state<
cuda::thread_scope::thread_scope_block,
stages_count
> shared_state;
cuda::pipeline pipeline = cuda::make_pipeline(block, &shared_state, thread_role);
// Each thread block processes `batch_sz` batches.
// Compute offset of the batch `batch` of this thread block in global memory:
auto block_batch = [&](size_t batch) -> int {
return elements_per_batch * batch + elements_per_batch_per_block * blockIdx.x;
};
for (size_t compute_batch = 0, fetch_batch = 0; compute_batch < batch_sz; ++compute_batch) {
// The outer loop iterates over the computation of the batches
for (; fetch_batch < batch_sz && fetch_batch < (compute_batch + stages_count); ++fetch_batch) {
// This inner loop iterates over the memory transfers, making sure that the pipeline is always full
if (thread_role == cuda::pipeline_role::producer) {
// Only the producer threads schedule asynchronous memcpys:
pipeline.producer_acquire();
size_t shared_idx = fetch_batch % stages_count;
size_t batch_idx = fetch_batch;
size_t global_batch_idx = block_batch(batch_idx) + thread_idx;
size_t shared_batch_idx = shared_offset[shared_idx] + thread_idx;
cuda::memcpy_async(shared + shared_batch_idx, global_in + global_batch_idx, sizeof(int), pipeline);
pipeline.producer_commit();
}
}
if (thread_role == cuda::pipeline_role::consumer) {
// Only the consumer threads compute:
pipeline.consumer_wait();
size_t shared_idx = compute_batch % stages_count;
size_t global_batch_idx = block_batch(compute_batch) + thread_idx;
size_t shared_batch_idx = shared_offset[shared_idx] + thread_idx;
compute(global_out + global_batch_idx, *(shared + shared_batch_idx));
pipeline.consumer_release();
}
}
}
Tensor Memory Accelerator (TMA)
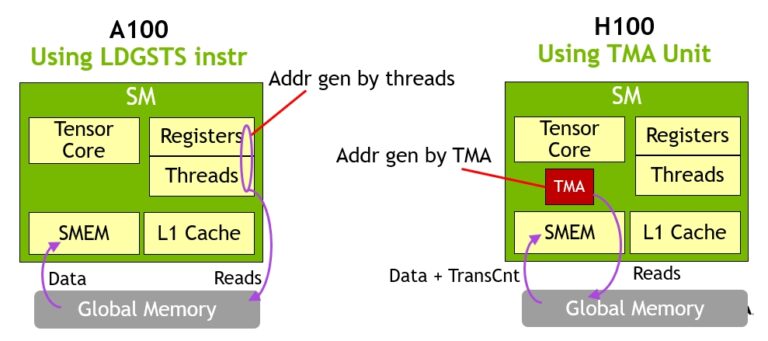
- 这篇文章前文都是普通异步拷贝,适用拷贝少量数据的场景,TMA是批量异步拷贝,适合拷贝大量数据
- TMA支持一维tensor拷贝(不需要 tensor map)和多维tensor拷贝(需要 tensor map)
- tensor map一般是在主机端创建,然后传入算子中使用
- TMA在PTX层由
cp.async.bulk指令实现 - TMA支持多个异步拷贝完成机制

TMA的功能
- GMEM<->SMEM双向拷贝
- 一个cluster里不同SMEM之间的拷贝
- multicast模式: GMEM->一个cluster里的多个SMEM。Hopper only,non-Hopper性能差。
TMA拷贝一维数据
#include <cuda/barrier>
#include <cuda/ptx>
using barrier = cuda::barrier<cuda::thread_scope_block>;
namespace ptx = cuda::ptx;
static constexpr size_t buf_len = 1024;
__global__ void add_one_kernel(int* data, size_t offset)
{
// Shared memory buffer. The destination shared memory buffer of
// a bulk operations should be 16 byte aligned.
__shared__ alignas(16) int smem_data[buf_len];
// 1. a) Initialize shared memory barrier with the number of threads participating in the barrier.
// b) Make initialized barrier visible in async proxy.
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier bar;
if (threadIdx.x == 0) {
init(&bar, blockDim.x); // a)
ptx::fence_proxy_async(ptx::space_shared); // b)
}
__syncthreads();
// 2. Initiate TMA transfer to copy global to shared memory.
if (threadIdx.x == 0) {
// 3a. cuda::memcpy_async arrives on the barrier and communicates
// how many bytes are expected to come in (the transaction count)
cuda::memcpy_async(
smem_data,
data + offset,
cuda::aligned_size_t<16>(sizeof(smem_data)),
bar
);
}
// 3b. All threads arrive on the barrier
barrier::arrival_token token = bar.arrive();
// 3c. Wait for the data to have arrived.
bar.wait(std::move(token));
// 4. Compute saxpy and write back to shared memory
for (int i = threadIdx.x; i < buf_len; i += blockDim.x) {
smem_data[i] += 1;
}
// 5. Wait for shared memory writes to be visible to TMA engine.
ptx::fence_proxy_async(ptx::space_shared); // b)
__syncthreads();
// After syncthreads, writes by all threads are visible to TMA engine.
// 6. Initiate TMA transfer to copy shared memory to global memory
if (threadIdx.x == 0) {
ptx::cp_async_bulk(
ptx::space_global,
ptx::space_shared,
data + offset, smem_data, sizeof(smem_data));
// 7. Wait for TMA transfer to have finished reading shared memory.
// Create a "bulk async-group" out of the previous bulk copy operation.
ptx::cp_async_bulk_commit_group();
// Wait for the group to have completed reading from shared memory.
ptx::cp_async_bulk_wait_group_read(ptx::n32_t<0>());
}
}
TMA拷贝多维数据
创建tensor map
CUtensorMap tensor_map{};
// rank is the number of dimensions of the array.
constexpr uint32_t rank = 2;
uint64_t size[rank] = {GMEM_WIDTH, GMEM_HEIGHT};
// The stride is the number of bytes to traverse from the first element of one row to the next.
// It must be a multiple of 16.
uint64_t stride[rank - 1] = {GMEM_WIDTH * sizeof(int)};
// The box_size is the size of the shared memory buffer that is used as the
// destination of a TMA transfer.
uint32_t box_size[rank] = {SMEM_WIDTH, SMEM_HEIGHT};
// The distance between elements in units of sizeof(element). A stride of 2
// can be used to load only the real component of a complex-valued tensor, for instance.
uint32_t elem_stride[rank] = {1, 1};
// Get a function pointer to the cuTensorMapEncodeTiled driver API.
auto cuTensorMapEncodeTiled = get_cuTensorMapEncodeTiled();
// Create the tensor descriptor.
CUresult res = cuTensorMapEncodeTiled(
&tensor_map, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_INT32,
rank, // cuuint32_t tensorRank,
tensor_ptr, // void *globalAddress,
size, // const cuuint64_t *globalDim,
stride, // const cuuint64_t *globalStrides,
box_size, // const cuuint32_t *boxDim,
elem_stride, // const cuuint32_t *elementStrides,
// Interleave patterns can be used to accelerate loading of values that
// are less than 4 bytes long.
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
// Swizzling can be used to avoid shared memory bank conflicts.
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE,
// L2 Promotion can be used to widen the effect of a cache-policy to a wider
// set of L2 cache lines.
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
// Any element that is outside of bounds will be set to zero by the TMA transfer.
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE
);
把tensor map从host拷贝到device
#include <cuda.h>
__global__ void kernel(const __grid_constant__ CUtensorMap tensor_map)
{
// Use tensor_map here.
}
int main() {
CUtensorMap map;
// [ ..Initialize map.. ]
kernel<<<1, 1>>>(map);
}
用tensor map完成TMA拷贝。下面的算子从一个更大的二维数组中加载一个大小为 SMEM_HEIGHT x SMEM_WIDTH 的二维块(tile)。该块的左上角由索引 x 和 y 指定。该块首先被加载到SMEM中,经过修改后,再写回GMEM。
#include <cuda.h> // CUtensormap
#include <cuda/barrier>
using barrier = cuda::barrier<cuda::thread_scope_block>;
namespace cde = cuda::device::experimental;
__global__ void kernel(const __grid_constant__ CUtensorMap tensor_map, int x, int y) {
// The destination shared memory buffer of a bulk tensor operation should be
// 128 byte aligned.
__shared__ alignas(128) int smem_buffer[SMEM_HEIGHT][SMEM_WIDTH];
// Initialize shared memory barrier with the number of threads participating in the barrier.
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier bar;
if (threadIdx.x == 0) {
// Initialize barrier. All `blockDim.x` threads in block participate.
init(&bar, blockDim.x);
// Make initialized barrier visible in async proxy.
cde::fence_proxy_async_shared_cta();
}
// Syncthreads so initialized barrier is visible to all threads.
__syncthreads();
barrier::arrival_token token;
if (threadIdx.x == 0) {
// Initiate bulk tensor copy.
cde::cp_async_bulk_tensor_2d_global_to_shared(&smem_buffer, &tensor_map, x, y, bar);
// Arrive on the barrier and tell how many bytes are expected to come in.
token = cuda::device::barrier_arrive_tx(bar, 1, sizeof(smem_buffer));
} else {
// Other threads just arrive.
token = bar.arrive();
}
// Wait for the data to have arrived.
bar.wait(std::move(token));
// Symbolically modify a value in shared memory.
smem_buffer[0][threadIdx.x] += threadIdx.x;
// Wait for shared memory writes to be visible to TMA engine.
cde::fence_proxy_async_shared_cta();
__syncthreads();
// After syncthreads, writes by all threads are visible to TMA engine.
// Initiate TMA transfer to copy shared memory to global memory
if (threadIdx.x == 0) {
cde::cp_async_bulk_tensor_2d_shared_to_global(&tensor_map, x, y, &smem_buffer);
// Wait for TMA transfer to have finished reading shared memory.
// Create a "bulk async-group" out of the previous bulk copy operation.
cde::cp_async_bulk_commit_group();
// Wait for the group to have completed reading from shared memory.
cde::cp_async_bulk_wait_group_read<0>();
}
// Destroy barrier. This invalidates the memory region of the barrier. If
// further computations were to take place in the kernel, this allows the
// memory location of the shared memory barrier to be reused.
if (threadIdx.x == 0) {
(&bar)->~barrier();
}
}
资料
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#asynchronous-simt-programming-model
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#asynchronous-barrier
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#memcpy-async-barrier
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#asynchronous-data-copies
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#asynchronous-data-copies-using-the-tensor-memory-accelerator-tma
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#encoding-a-tensor-map-on-device
- https://nvidia.github.io/cccl/libcudacxx/extended_api/synchronization_primitives/barrier.html
- https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#parallel-synchronization-and-communication-instructions-mbarrier