Triton


Future Work
https://pytorch.org/blog/warp-specialization-in-triton-design-and-roadmap/
二八定律
巴莱特定律(Pareto Principle),又称二八定律或帕累托法则,是由意大利经济学家帕累托发现的,其核心思想是:在任何一组事物中,最重要的部分(关键少数)只占约20%,却能带来80%的成果(主要结果),而剩余80%的次要部分,仅带来20%的成果。此定律广泛应用于经济、管理、时间管理等领域,强调应聚焦于那关键的20%投入,以获得主要的80%产出。
主要内容
- 关键少数 vs. 次要多数:20%的关键因素(如核心客户、重要任务、核心产品)对整体(80%的效益)起决定性作用。
- 非均衡性:大多数结果并非平均分配,而是呈现出显著的不平衡状态。
应用领域与实例
- 企业管理:20%的客户贡献80%的利润;80%的销售额来自20%的商品。
- 时间管理:80%的成果源于20%的有效时间投入。
- 资源分配:将80%的资源投入到能产生80%效益的20%的关键领域。
- 个人发展:专注于20%的核心技能或知识,实现80%的进步。
- 社会财富:早期观察到20%的人口掌握了80%的财富。
实际意义 巴莱特定律指导人们识别和聚焦于“关键少数”,避免在次要的80%上耗费过多精力,从而更高效地分配有限的资源,以最小的投入获得最大的回报。
https://en.wikipedia.org/wiki/Pareto_front
Triton总览
CUDA vs Triton (例子:向量加)
__global__ void add_kernel(float* a, float* b, float* c, int n) {
// 1. Manually calculate the global index of this specific thread
int i = blockIdx.x * blockDim.x + threadIdx.x;
// 2. Add a boundary check (if the vector isn't a perfect multiple of block size)
if (i < n) {
c[i] = a[i] + b[i];
}
}
import triton
import triton.language as tl
@triton.jit
def add_kernel(a_ptr, b_ptr, c_ptr, n, BLOCK_SIZE: tl.constexpr):
# 1. Get the starting point for this "program" (tile)
pid = tl.program_id(0)
# 2. Create a vector of offsets (e.g., [0, 1, 2, ... 1023])
offsets = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
# 3. Use a mask for boundary conditions (instead of an 'if' statement)
mask = offsets < n
# 4. Load, Add, and Store the entire tile at once
a = tl.load(a_ptr + offsets, mask=mask)
b = tl.load(b_ptr + offsets, mask=mask)
output = a + b
tl.store(c_ptr + offsets, output, mask=mask)
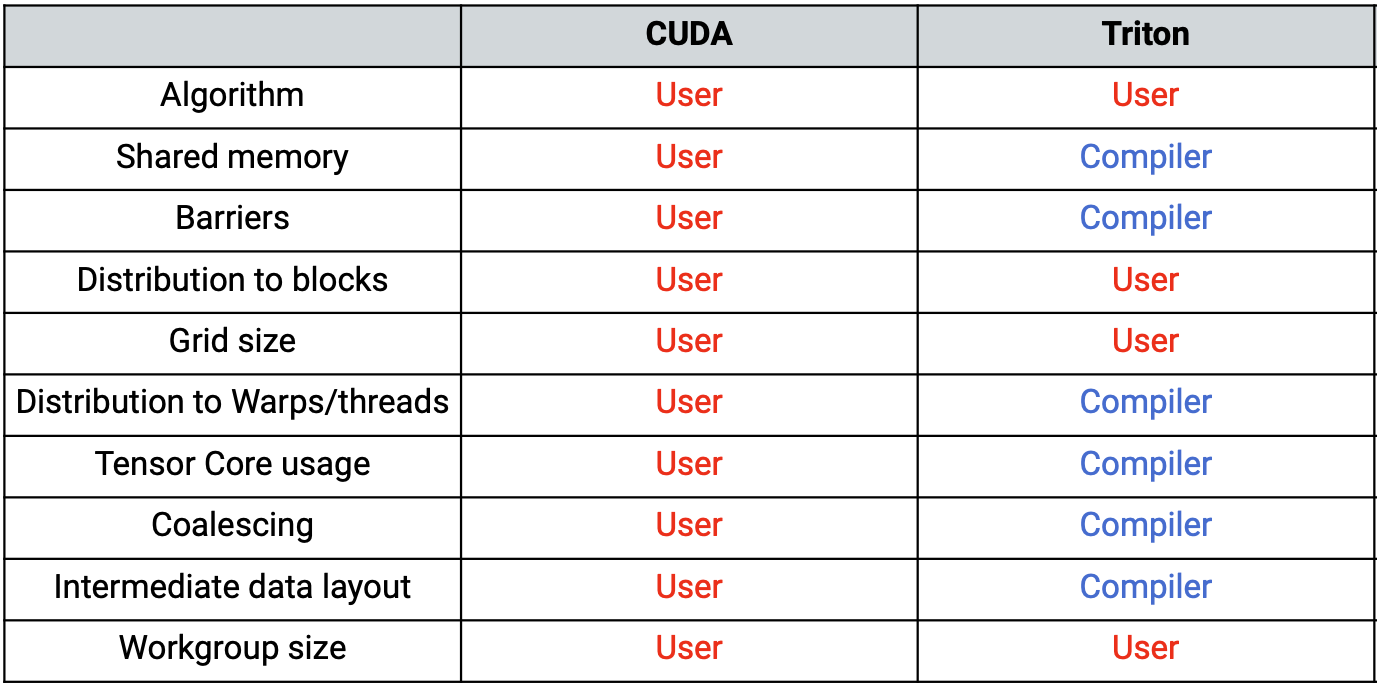
- Triton 是一种中间语言及编译器,其设计初衷是通过实现基于分块的神经网络计算的高效可移植方案,突破现有厂商库在新型深度学习算子上的局限性。
- Triton 采用分块架构(这里的 “分块” 指张量中一个小型的矩形子区域)。相比之下,XLA 基于完整张量运行,开发者无法对其子张量进行操作。
- Triton是一种取舍 : portability / productivity / efficiency
- Triton 开创了Tile编程,但和CUDA一样,还是SPMD

- Triton的性能预期:高下限,低上限,低指 > 80% SoL
- Triton支持的硬件: GPU, CPU, Accelerator

Triton的未来目标
如果说某一模型的运行效率达到 “理论性能上限的 80%”,意思就是该模型对应的代码,实现了硬件(如英伟达 H100 显卡)物理层面可承载的最大理论吞吐量的 80%。

| 2024 | 2025 |
|---|---|
 |
 |
Triton-C / Triton-Python
- Tile Declarations: Special syntax for multi-dimensional arrays, e.g.,
int tile[16, 16]. Tile shapes are constant but can be tunable for compiler optimization. - Built-in Functions:
dot,transfor matrix operations, andget_global_range(axis)for retrieving thread-block global indices. - Broadcasting: Numpy-like broadcasting semantics using
newaxisand slicing (e.g.,range[:, newaxis]). - Predication: Basic control-flow within tile operations is achieved through predicated statements using the
@prefix, allowing partial guarding of tile-level loads.
The semantics of Triton-C provide:
- Tile Semantics: Abstract away low-level performance details like memory coalescing, cache management, and specialized hardware utilization, allowing the compiler to optimize them automatically.
- Broadcasting Semantics: A two-step process: (1) padding the shorter operand with ones until dimensionalities match, and (2) replicating content to match shapes.
- SPMD Programming Model: Similar to CUDA, but each kernel is single-threaded and automatically parallelized, operating on a set of
get_global_range(axis)values. This simplifies kernels by removing explicit CUDA-like concurrency primitives.
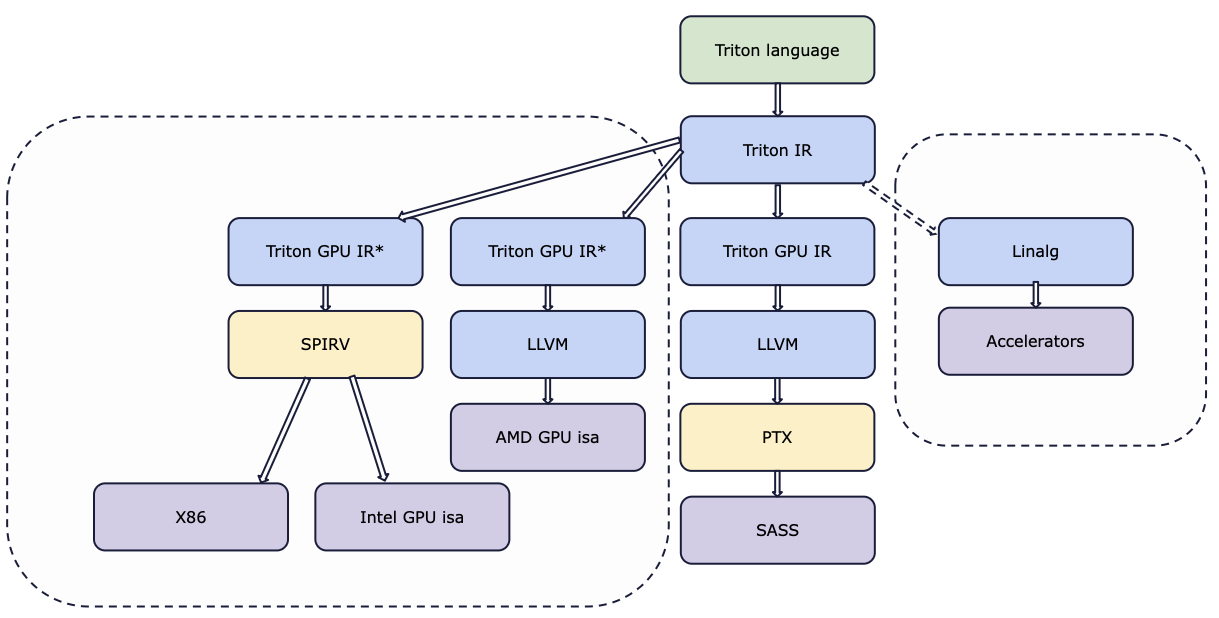
Triton IR
Triton-IR is an LLVM/MLIR-based IR designed for tile-level program analysis, transformation, and optimization. It shares LLVM-IR’s module, function, and basic block structure, utilizing Static Single Assignment (SSA) form. Its key extensions include:
- Tile Types: Multi-dimensional types, e.g.,
i32<8,8>, represent tiles. Parametric tunable shapes from Triton-C are resolved by the JIT compiler. - Tile-Level Data-Flow Instructions:
- Retiling Instructions: reshape creates a tile of specified shape from input data (useful for re-interpreting variables), and broadcast replicates an input tile along unit dimensions.
- Scalar instructions (e.g., cmp, add, load) are extended to signify element-wise operations on tile operands.
- Specialized arithmetic instructions: trans (transposition) and dot (matrix multiplication).
- Tile-Level Control-Flow Analysis: To handle divergent control flow within tiles (where branching is not feasible), Triton-IR introduces Predicated SSA (PSSA) and \(\psi\)-functions:
- cmpp instruction: Similar to cmp, but returns two opposite boolean predicates.
- psi instruction: Merges values from different streams of predicated instructions, ensuring correctness when operations are conditionally applied to tile elements.
编译Passes
| 编译过程 | 编译pipeline |
|---|---|
 |
 |
编译Passes (详细)
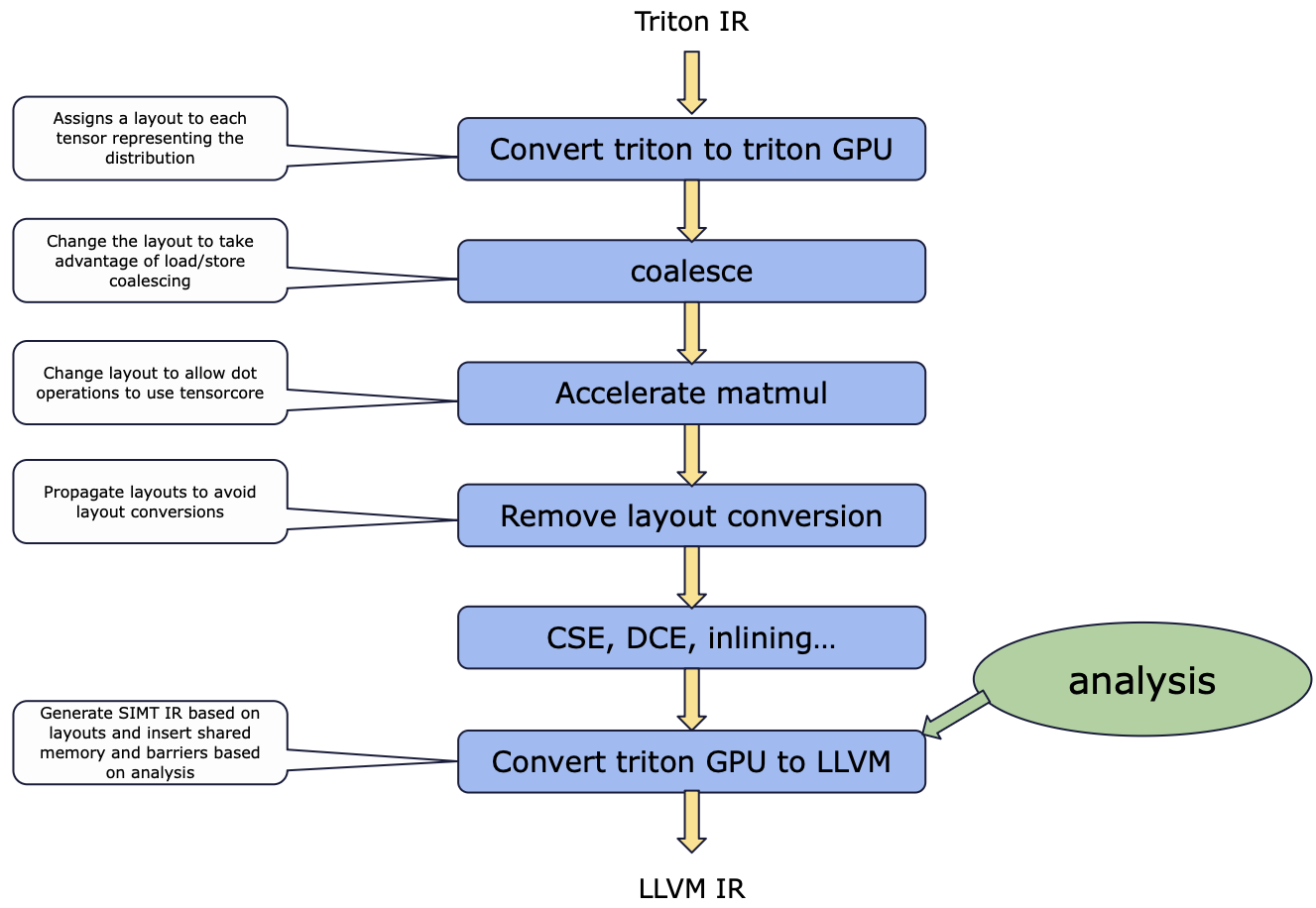
The Triton-JIT compiles and optimizes Triton-IR programs into efficient machine code through a series of passes and an auto-tuning engine:
-
Machine-Independent Passes: Pre-Fetching: Automatically detects loops and inserts prefetching code to hide memory latency. Tile-Level Peephole Optimization: Simplifies chains of tile operations using algebraic properties (e.g., \(X = (X^T)^TX=(XT)TX = (X^T)^TX=(XT)T)\).
- Machine-Dependent Passes: These passes are designed for GPU architectures with hierarchical memory.
- Hierarchical Tiling: Decomposes tiles into micro-tiles and nano-tiles to map computations optimally to the hardware’s compute capabilities and memory hierarchy. The structure of Triton-IR allows automatic enumeration and optimization of nested tiling configurations.
- Memory Coalescing: Orders threads within micro-tiles to ensure adjacent threads access nearby memory locations, reducing memory transactions to DRAM.
- Shared Memory Allocation: Determines when and where to store tile operands in fast shared memory by analyzing variable live ranges and employing a linear-time allocation algorithm.
- Shared Memory Synchronization: Automatically inserts barriers in the generated GPU code to preserve program correctness by detecting Read-After-Write (RAW) and Write-After-Read (WAR) hazards using forward data-flow analysis with equations:
- Auto-tuner: Optimizes meta-parameters associated with the optimization passes (e.g., tiling parameters). In this work, it uses an exhaustive search over powers of two for tile, micro-tile, and nano-tile sizes.
早期挑战
The main challenge posed by our proposed paradigm is that of work scheduling, i.e., how the work done by each program instance should be partitioned for efficient execution on modern GPUs. To address this issue, the Triton compiler makes heavy use of block-level data-flow analysis, a technique for scheduling iteration blocks statically based on the control- and data-flow structure of the target program. The resulting system actually works surprisingly well: our compiler manages to apply a broad range of interesting optimization automatically (e.g., automatic coalescing, thread swizzling, pre-fetching, automatic vectorization, tensor core-aware instruction selection, shared memory allocation/synchronization, asynchronous copy scheduling). Of course doing all this is not trivial; one of the purposes of this guide is to give you a sense of how it works.
当前挑战 Pipelining
Hand-fused loops in matmul kernel, multitude of functional and performance problems ● Matmul optimized path not ready for branching in the main loop ■ WGMMA pipelining 💀 ■ Layout conversion optimizations 😵 ■ Axis Analysis 🪦
● IfOp placement in the loop - major performance problem ■ Placed in the middle of the loop ■ Instruction scheduling off the window ■ Introduced CoarseSchedule, allowing for better control over ops placement
https://drive.google.com/file/d/1NOZ2LIZgHs3UQKCEw3Nv5rrChlX2bzZ0/view?usp=drive_link https://www.youtube.com/watch?v=PAsL680eWUw
CPU Support
● OSS demands for computers without GPU
● Internal business demands
○ Small batch jobs, PyTorch for Edge (20% efforts for 80% perf)
Compiler Overview (third_party/cpu/backend/compiler.py)
▪ make_ttir: high-level optimizations (same with GPU) ▪ make_ttcir: TTIR → TTCIR, lowering to vector dialect ▪ make_tttcir: TTCIR → Target-specific TTCIR (TTTCIR) ▪ make_llir: Target-specific TTCIR → LLVM IR ▪ make_asm: LLVM IR to .asm (static compilation) ▪ make_so: Compile .asm into .so ▪ The CPU driver and OpenMP launcher
MTIA Support
Meta的反馈:
- Need for improved support for memory subsystems
- Need for improved support for asynchronous execution
- Need for supporting cross-PE primitives and PE topology-aware codegen for custom HW targets
Hopper Support


Hopper added a lot of complexity, so would Ascend
memory coalescing: Orders threads within micro-tiles to ensure adjacent threads access nearby memory locations, reducing memory transactions to DRAM.
prefetch: prefetch from shared memory the operands (A and B) of a tt.dot, when this operation is located in a loop.
reorder_instructions: reorder instructions so as to (1) decrease register pressure (e.g., by moving conversions from shared memory before their first use) and (2) promote LLVM instruction order more friendly to ptxas.
https://github.com/triton-lang/triton/blob/167bdc81e7b563433fa65980eed4f609a727c74e/include/triton/Dialect/TritonGPU/Transforms/Passes.td

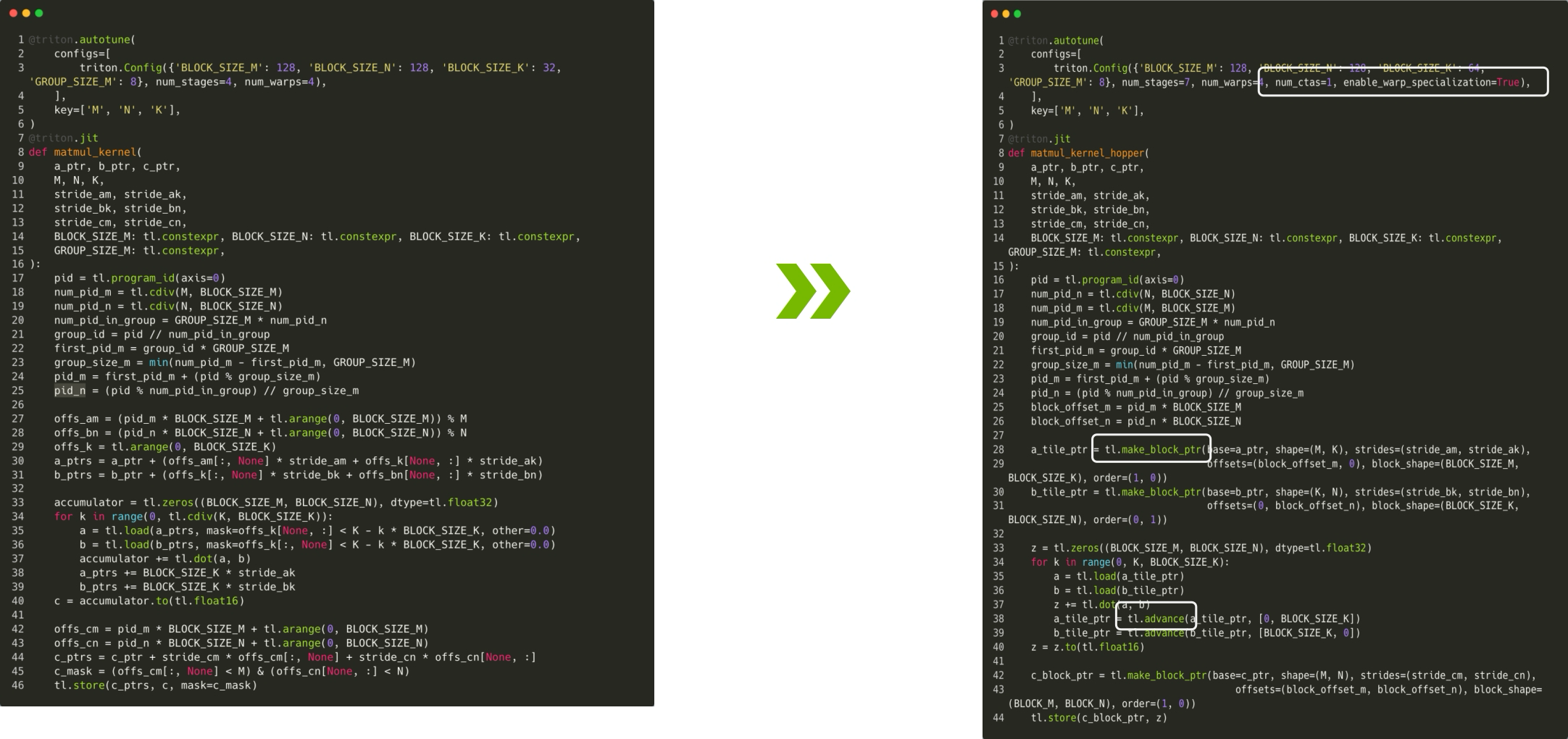
make_block_ptr: a new semantics: block pointer, which makes users easier & faster to load a block from a parent tensor.
Blackwell Support & Gluon
为什么需要Gluon
Why: achieving >80% SoL with the Triton middle-end is becoming intractable: (Flash Attention on Blackwell is the motivating case for inventing Gluon)
- Kernels are becoming more complex
- Hardware is gaining more degrees of freedom
- As the tensor core programming becomes increasingly complex: warp-specialization, async MMA, async TMA, it becomes very hard for triton compiler to find a optimal schedule to maximize performance. Hence more control of schedule should be exposed to the deveropers so that they could express the schedule easily, then triton compiler could do the rest.
Concrete problems:
- Optimal tensor layout assignment in registers and in memory
- Warp specialization partitioning and loop scheduling
- Clever synchronization tricks to squeeze more loop stages
Gluon和Triton的异同
- 相同:保持tile编程模型,保持SPMD
- 不同:Gluon对开发者开放控制权: 1. 布局 2. 调度 3. 内存
Gluon简介
暂时不支持Gluon和Triton混合编程 (as of 2025). (I think it’s the same situation as “C++ with inline assembly”, need a good use-case and then define a clera boundary, then it should work)
Gluon is a GPU programming language based on the same compiler stack as Triton. But unlike Triton, Gluon is a lower-level language that gives the user more control and responsibility when implementing kernels.
At a high level, Gluon and Triton share many similarities. Both implement a tile-based SPMD programming model, where tiles represent N-dimensional arrays distributed over a “program”. Both are Python DSLs sharing the same frontend and JIT infrastructure.
Triton, however, abstracts many details of implementing kernels and GPU hardware from the user. It defers to the compiler to manage tile layouts, memory allocation, data movement, and asynchronity.
Getting these details right is important to kernel performance. While the Triton compiler does a good job of generating efficient code for a wide range of kernels, it can be beaten by hand-tuned low-level code. When this happens, there is little the user can do to significantly improve performance since all the details are hidden.
In Gluon, these details are exposed to the user. This means writing Gluon kernels requires a deeper understanding of GPU hardware and the many aspects of GPU programming, but it also enables writing more performant kernels by finely controlling these low-level details.
Gluon has language support for warp-specialization.
Linear Layouts
Triton linear layout is target-independent. Before, Triton’s layout representation is target-dependent.
Gluon vs Cutlass cute
While both CUTE and linear layouts aim to address the challenge of flexible task mapping on emerging architectures, they differ in several key aspects. First and foremost, CUTE is primarily designed for users to manually describe layouts, whereas linear layouts are integrated into a compiler. Second, the linear algebra framework of linear layouts enables compilers to generate efficient code for layout conversion and code lowering for many common operators, which is absent in CUTE. Third, swizzling is inherently defined within linear layouts, whereas in CUTE, it is treated as a separate step
https://www.lei.chat/posts/triton-compiler-development-tips/
Liger Kernel
Liger Kernel is an open source library of optimized Triton kernels designed to enhance the efficiency and scalability of training Large Language Models (LLMs). It focuses on kernel-level optimizations such as operation fusing and input chunking, achieving significant improvements in training throughput and GPU memory usage compared to existing implementations like those from HuggingFace. By using a single line of code, Liger Kernel can improve training throughput by 20% and reduce memory usage by 60%.
NOTE Trition is expressive enough to have operation fusing and input chunking optimization.
Triton-Distributed
TODO
Profiling
Proton(profiling for Triton)
总结
Triton 的流水编排控制不够。如果要保持当前的应用性,要么硬件需要加更多的流水辅助能力。要么就要让Triton的抽象层次低一些暴露更多控制的能力。
Triton has trouble maintaining both 80% SoL and portability
Triton does not support multi-CTA well (DSMEM, Hopper/Blackwell)
Triton/Gluon composition vs C++/Assembly composition
user want FAST AND EASY gpu programming language. BOTH FAST AND EASY; For a specific task, user decide what’s kind of performance is acceptable, then they want to reach that performance goal ASAP. FAST first, then trade productivity for < 20% perf drop is acceptable.
80% SoL (AKA 80/20 rule matters for prototying and Triton’s main use case is prototyping, for example, flash-linear-attention)
Ascend will have the same problem as Hopper / Blackwell: precise control is needed to have 80% SoL
Autotuning is important for Ascend
Debugging experiences are important (python/AST/MLIR/LLVMIR/ELF, too many layers to get debuginfo right)
People like Python or DSL. Adopt Python-first strategy instead of “we support Python”
Attention-oriented (or whatever ops trending LLM needs), because that’s the most important use case
Windows-support
参考资料
https://pytorch.org/blog/triton-kernel-compilation-stages/